数据分析之MySQL学习
参考课程:戴师兄数据分析
原始幕布格式笔记:戴师兄数据分析启蒙课:SQL基础语法+运行原理+云端数据库搭建.opml,提取码: jb27
基础语法
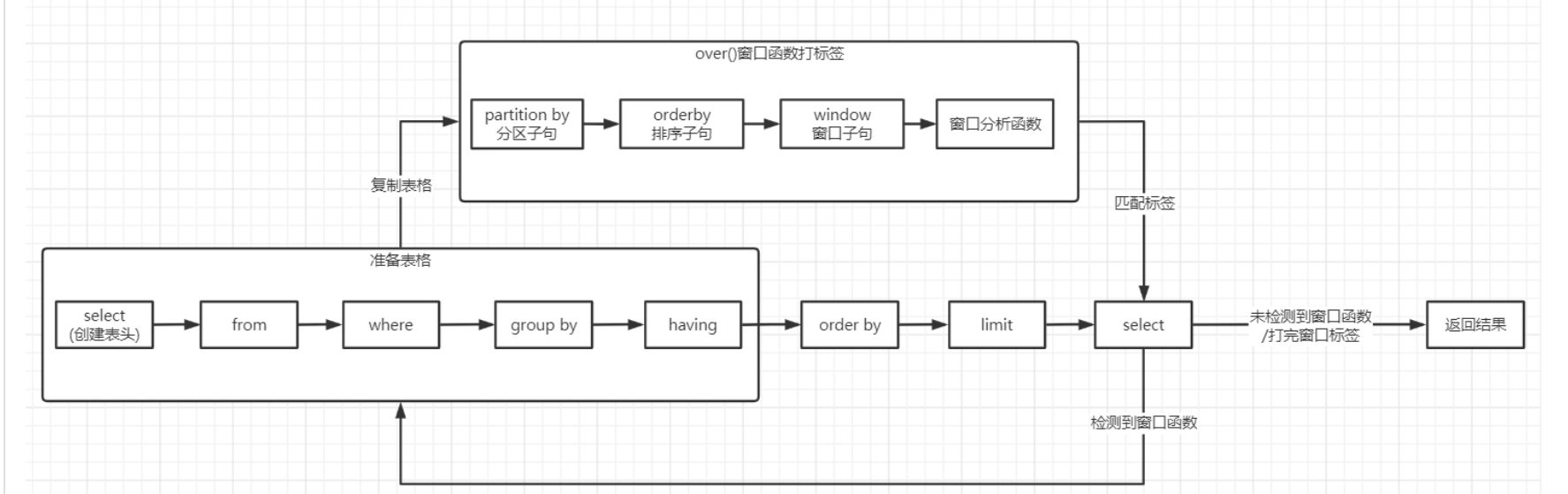
语法结构:select--from--where--group by--having--order by--limit
运行顺序:from--where--group by--having--order by--limit--select
select
select 字段名 from 表名 #字段名决定了查询后显示的字段 表明指定了这一查询涉及的数据来源
#select和from要加空格 单段代码句末不需要加分号,多段最好加上分号
select * from 表明 #查询所有项(所有列)
select name as 姓名, population 人口 from 表名 #为字段添加别名 as可有可无
select distinct 字段名, 字段名 from 表名 #有多个字段时候,distinct是紧跟在select后面,不能放到中间字段, #distinct是对这几个字段组成的行去重行数据
select name, gdp, population, gdp/population 人均GDP from world #可以进行简单的计算
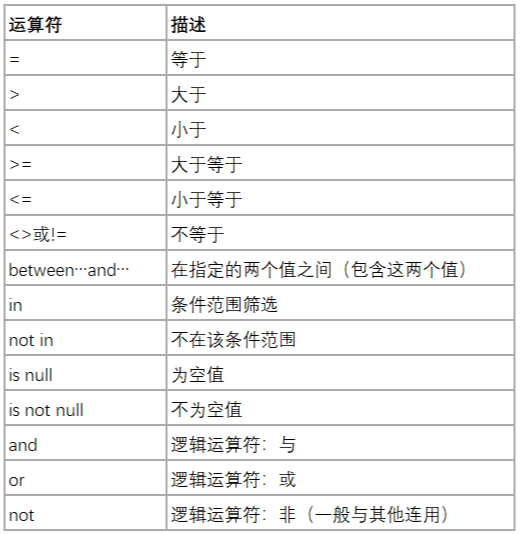
where
select 字段名 from 表名 where 表达式(字段名 表达式 值) #限定查询行必须满足的条件
select name,population from world where name='Germany' #查询德国的人口
SELECT name,gdp FROM world WHERE gdp between 2550010 and 255001000
select name,population from world where name in ('Sweden', 'Norway', 'Denmark')
注意 is null用于查询空值(null),不等于0也不等于null字符串
select 字段名 from world where 字段名 like '通配符+字符'
select name,population from world where name like '_t%' #查询第二个字符是t的国家名称和人口
where子句的表达式中除了使用运算符来进行条件判断,还可以使用like操作符组合通配符进行模糊查询,通配符用来匹配值的一部分,跟在like后面进行数据过滤常用的通配符有%和_,%用来匹配多个字符可以是零个、一个也可以是多个字符,_仅能用来匹配单个字符- between包含边界,如果不想包含边界,可以加个条件使用
!=来排除
order by
select 字段名 from 表名
where 表达式
order by 字段名 asc|desc #规定查询出的结果集显示的顺序,desc为降序,asc为升序,默认不写为升序
SELECT winner, yr, subject FROM nobel WHERE winner like 'Sir%' order by yr desc, winner asc
order by subject in ('chemistry','physics') , subject, winner #subject in ()在括号内的为1,不在为0,可以把数据排在最前或者最后
limit
limit [位置偏移量x,]行数n # 限制查询结果集显示的行数,第一行的位置偏移量是0,从x+1行开始返回n行
聚合函数和group by
AVG() SUM() COUNT() COUNT() MAX() MIN()
group by 字段1,字段2
聚合函数适用于需要获取数据的汇总信息,例如某字段行数、某字段平均值、某字段中最大最小数等
having
having 表达式 #限定分组聚合后的查询行必须满足的条件,使用该子句是为了对group by分组后的数据进行筛选
总结:
标准语法
select 字段名
from 表名
[where 表达式]
[group by 字段名]
[having 表达式]
[order by 字段名 asc|desc]
[limit [位置偏移量,]行数]
运行过程:
from--where--group by--having--order by--limit--select
- 执行from语句从数据库中调取复制一份表格
- 执行where语句在复制的表格中筛选出符合条件的数据行
- 执行group by语句依据指定字段对筛选后的数据分区,将依据的字段去重分组,相当于Excel建立了一个数据透视表,添加了行标签
- 执行having语句筛选满足条件的分组
- 执行order by语句对筛选后的数据进行排序
- 执行limit语句对排序后的数据限制显示的行
- 执行select语句,提取最后要显示的字段
常见函数
- 数学函数round(x,y)——四舍五入函数
- round函数对x值进行四舍五入,精确到小数点后y位
- y为负值时,保留小数点左边相应的位数为0,不进行四舍五入
- 例如:round(3.15,1)返回3.2,round(14.15,-1)返回10
- 字符串函数concat(s1,s2,…)——连接字符串函数
- concat函数返回连接参数s1、s2等产生的字符串
- 任一参数为null时,则返回null
- 例如:concat(‘My’,’ ‘,’SQL’)返回My SQL,concat(‘My’,null,’SQL’)返回null
- replace函数使用字符串s2代替s中所有的s1
- 例如:replace(‘MySQLMySQL’,’SQL’,’sql’)返回MysqlMysql
- left函数返回字符串s最左边n个字符
- right函数返回字符串s最右边n个字符
- substring函数返回字符串s从第n个字符起取长度为len的子字符串,n也可以为负值,则从倒数第n个字符起取长度为len的子字符串,没有len值则取从第n个字符起到最后一位
- 例如:left(‘abcdefg’,3)返回abc,right(‘abcdefg’,3)返回efg,substring(‘abcdefg’,2,3)返回bcd,substring(‘abcdefg’,-2,3)返回fg,substring(‘abcdefg’,2)返回bcdefg
- 数据类型转换函数cast(x as type)——转换数据类型的函数
- cast函数将一个类型的x值转换为另一个类型的值
- type参数可以填写char(n)、date、time、datetime、decimal等转换为对应的数据类型
- 日期时间函数year(date)、month(date)、day(date)——获取年月日的函数
- date可以是年月日组成的日期,也可以是年月日时分秒组成的日期时间
- year(date)返回日期格式中的年份,month(date)返回日期格式中的月份,day(date)返回年日期格式中的日份
- 例如:year(‘2021-08-03’)返回2021,month(‘2021-08-03’)返回8,day(‘2021-08-03’)返回3
- date用来指定起始时间
- date可以是年月日组成的日期,也可以是年月日时分秒组成的日期时间
- expr用来指定从起始时间添加或减去的时间间隔
- type指示expr被解释的方式,type可以可以是以下值
- 主要使用红框中的值

- 主要使用红框中的值
- date_add函数对起始时间进行加操作,date_sub函数对起始时间进行减操作
- 例如:date_add(‘2021-08-03 23:59:59’,interval 1 second)返回2021-08-04 24:00:00,date_sub(‘2021-08-03 23:59:59’,interval 2 month)返回2021-06-03 23:59:59
- datediff函数由date1-date2计算出间隔的时间,只有date的日期部分参与计算,时间不参与
- 例如:datediff(‘2021-06-08′,’2021-06-01’)返回7,datediff(‘2021-06-08 23:59:59′,’2021-06-01 21:00:00’)返回7,datediff(‘2021-06-01′,’2021-06-08’)返回-7
'%Y-%m-%d'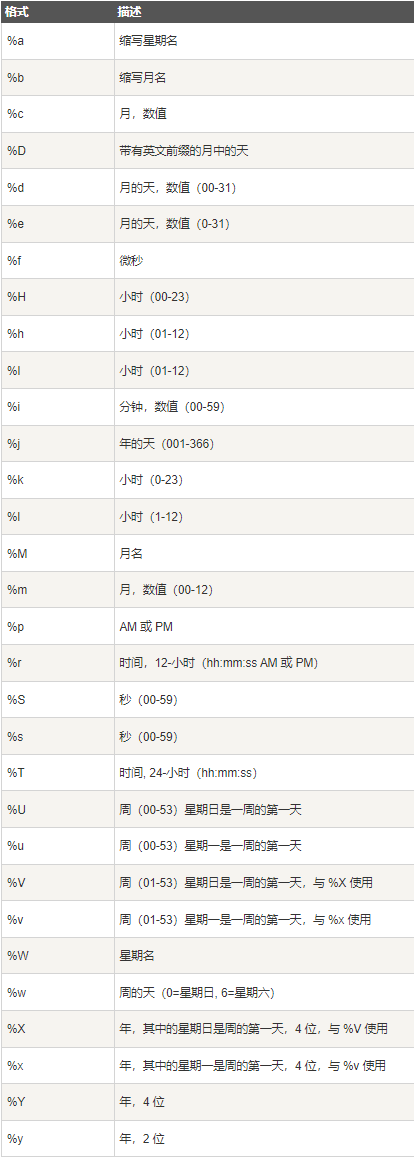
- 条件判断函数if(expr,v1,v2)
- 如果表达式expr是true返回值v1,否则返回v2
- 例如:if(1<2,’Y’,’N’)返回Y,if(1>2,’Y’,’N’)返回N
- case expr when v1 then r1 [when v2 then r2] …[else rn] end
- 例如:case 2 when 1 then ‘one’ when 2 then ‘two’ else ‘more’ end 返回two
- case后面的值为2,与第二条分支语句when后面的值相等相等,因此返回two
- case when v1 then r1 [when v2 then r2]…[else rn] end
- 例如:case when 1<0 then ‘T’ else ‘F’ end返回F
- 1<0的结果为false,因此函数返回值为else后面的F
高级语句
窗口函数
- 标准语法:
窗口函数over([partition by 字段名] [order by 字段名 asc|desc])窗口函数只能写在select中,over()中两个子句为可选项,partition by指定分区依据,order by指定排序依据 - 排序窗口函数
- rank()over() 跳跃排序 99 99 90 89 对应1 1 3 4
- dense_rank()over() 并列排序 99 99 90 89 对应1 1 2 3
- row_number()over() 连续性排序 99 99 90 89 对应1 2 3 4
- 偏移分析窗口函数
- lag(字段名,偏移量[,默认值])over()
- lead(字段名,偏移量[,默认值])over()
表连接
- 内连接 删除所有空值行
- select 字段名
- from 表名1 inner join 表名2 on 表名1.字段名 = 表名2.字段名
- 注意内连接inner可以省略,直接使用join默认为内连接
- 左连接 保留左边表所有的行
- select 字段名
- from 表名1 left join 表名2 on 表名1.字段名 = 表名2.字段名
- 右连接 保留右边表的所有行
- select 字段名
- from 表名1 right join 表名2 on 表名1.字段名 = 表名2.字段名
子查询
子查询本身就是一段完整的查询语句,然后用括号英文括号()包裹嵌套在主查询语句中,子查询可以多层嵌套,最常用的子查询运用在from和where子句中
- where子句中的子查询常用于查询条件无法一步到位,需要先进行一次查询,基于这个查询结果进行条件判断
- from子句中的子查询,本质上是通过一段查询代码,获得的数据作为主查询的数据来源;必须使用别名
云端数据库搭建
- 购买阿里云sql产品。
- 配置云数据库账号、数据库、白名单
- 安装datagrip连接数据库
- 安装sublime存储和打开sql文件
excel链接数据库
- 安装Mysql驱动
- 查看Excel是32位还是64位
- 配置ODBC
- Excel使用ODBC从MySQL获取数据
- 基于数据库获取的数据制作图表
tableau链接数据库
- 我们直接选择连接到服务器,选择Mysql,填写数据库参数
- 可以拖拽数据库,也可以写自定义SQL
